High‑dimensional biomedical datasets such as transcriptomics, proteomics, metabolomics, and multi‑omics require complex analytical workflows that integrate domain knowledge, statistical modeling, and reproducible reasoning. Current pipelines rely heavily on manual scripting, fragmented tools, and expert statisticians to generate hypotheses, select model families, infer distributions, and validate assumptions. Large language models can summarize literature but cannot reliably produce testable hypotheses, formal statistical equations, or distribution‑aware models that incorporate user data and data properties such as imbalance, high dimensionality, zero inflation, experiment of design, and diverse statistical distributions. This creates a critical need for an automated, evidence‑grounded analytical system that unifies hypothesis generation, model construction, and statistical validation.
Researchers at GW developed statLens, a novel AI‑driven analytical framework that integrates multi-agentic Retrieval‑Augmented Generation (RAG), LLM‑based reasoning, design‑of‑experiments (DoE) interpretation, and a distribution‑aware statistical engine to generate, refine, and execute complete statistical workflows. statLens transforms natural‑language study descriptions, and its measurements (omics, clinical, patient or sample characteristics data) into testable hypotheses, formal model equations, and validated statistical outputs, all stored in a structured knowledge mart that enables closed‑loop, self‑improving analytical performance and domain knowledge. This unified architecture provides transparent, reproducible, and expert‑level statistical modeling across diverse biomedical and experimental domains.
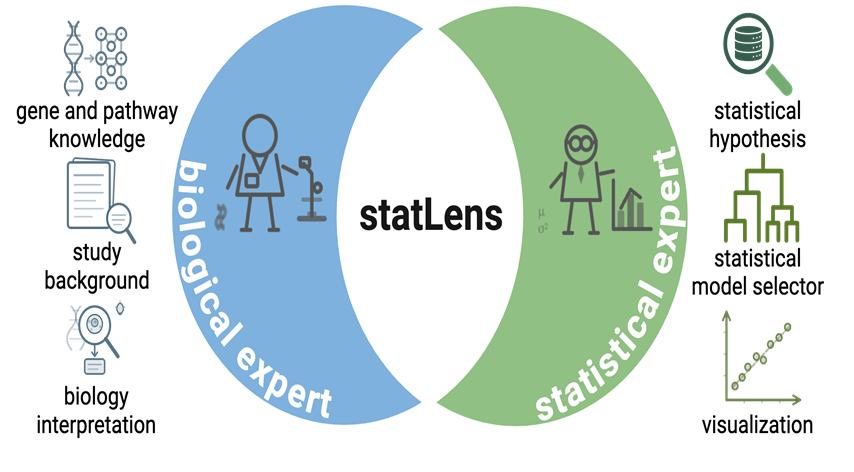
Figure 1. statLens is an AI-driven statistical intelligence system that bridges health, biological sciences, statistical methodology, and data science domains. It integrates structured study context, metadata, and omics data to support hypothesis generation, experimental design, model selection, equation formulation, and reproducible statistical execution. The framework combines a large language model–based planning layer with a deterministic statistical execution engine, enabling auditable, credit-metered analysis across diverse biomedical and multi-omics applications.
Advantages:
-
Improves modeling accuracy in high‑dimensional datasets.
-
Reduces reliance on expert statisticians.
-
Minimizes analytical errors and model mis‑specification.
-
Accelerates time‑to‑insight.
-
Enhances reproducibility and auditability.
Applications:
-
Accelerates multi‑omics and biomarker discovery.
-
Supports clinical‑trial analytics with automated modeling.
-
Enables precision‑medicine decision support.
-
Provides automated, reproducible DoE‑aligned modeling.